CRUST-Bench: A Benchmark for C-to-Safe-Rust Transpilation

C-to-Rust transpilation is a critical step for modernizing legacy C codebases, aiming to improve safety and integrate with modern Rust ecosystems. However, the field has lacked a standard dataset for evaluating whether a system can transpile C into safe, functionally correct Rust.
We introduce CRUST-Bench, a new benchmark designed to fill this gap. It consists of 100 C repositories, each paired with manually-written safe Rust interfaces and test cases to validate the correctness of the transpilation. By focusing on entire repositories instead of isolated functions, CRUST-Bench provides a realistic and challenging testbed for automated code migration.
The Challenge: From Unsafe C to Safe, Idiomatic Rust
The goal of C-to-Rust translation is not just ensuring functional equivalence; it involves a shift from C's non-memory-safe semantics to the memory-safe, idiomatic patterns of Rust. While Rust supports `unsafe` code, the primary benefit of migration is to produce code that leverages Rust 's compile-time safety guarantees, which can eliminate entire classes of memory bugs. This requires more than a simple syntactic conversion.
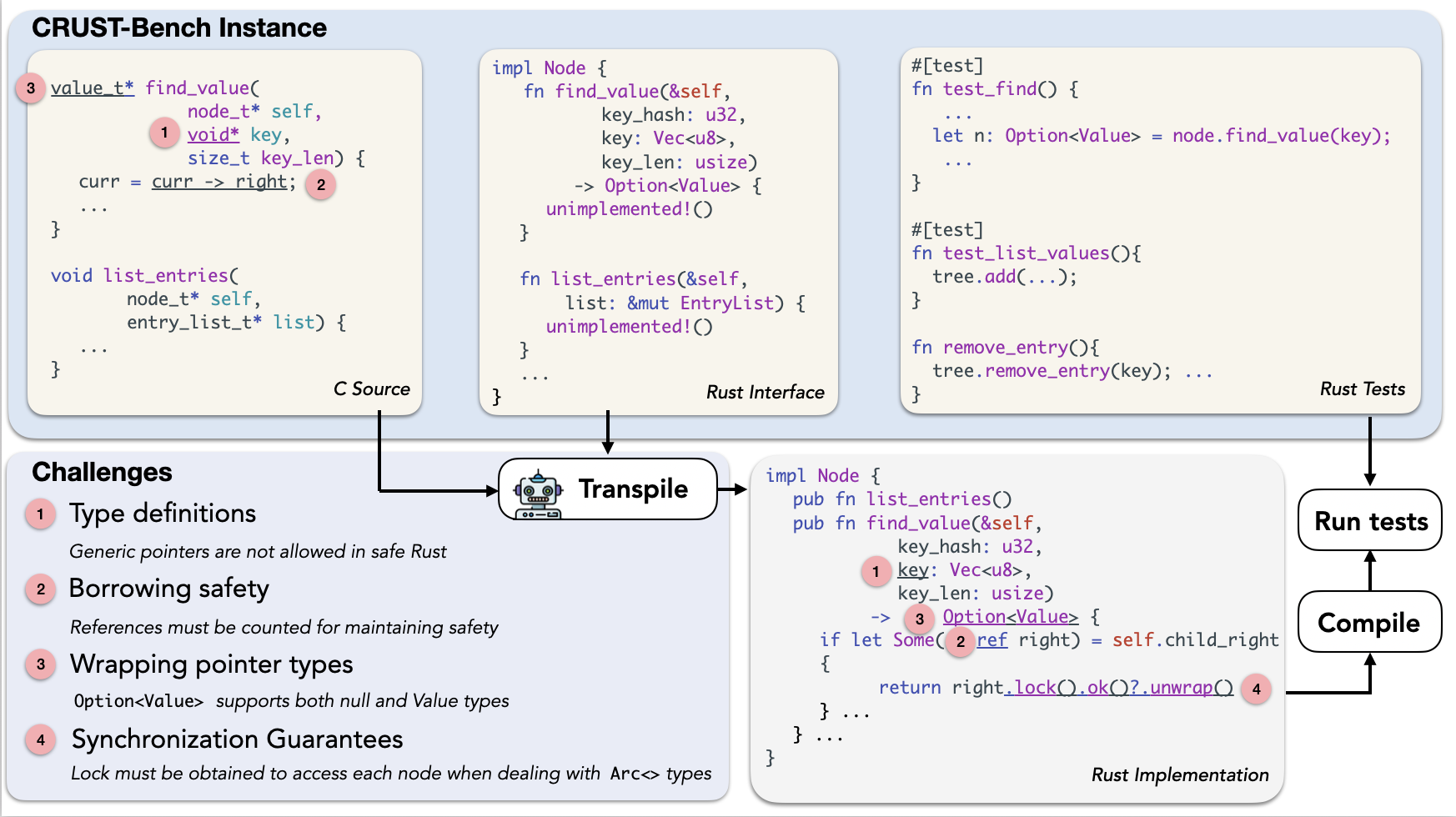
CRUST-Bench is designed to test this deep translation capability. A successful transpilation must produce Rust code that not only compiles without errors but also conforms to a predefined, idiomatic Rust interface and passes a suite of functional tests. As the figure above shows, this involves complex challenges like converting raw C pointers into safe, structured types like Vec<u8> and handling Rust 's strict borrowing and ownership rules.
Inside the CRUST-Bench Benchmark
Our benchmark contains 100 real-world C projects sourced from GitHub, with an average size of 958 lines of code, making them complex yet manageable for today 's LLMs. The projects span a diverse range of domains, including programming language infrastructure, data structures, system utilities, and networking.
- C Source Code: The original C repository, which can consist of multiple files with complex dependencies.
- Rust Interface: A manually-authored Rust interface that specifies the target function signatures, data structures, and ownership patterns. This interface guides the model to produce safe and idiomatic Rust. The interfaces feature significant complexity, with 56% of functions using reference arguments and 30% involving mutable references.
- Rust Tests: A suite of test cases, adapted from the original C project, to enforce the functional correctness of the transpiled Rust code.
How do State-of-the-Art Models Do?
We evaluated 8 frontier large language models on CRUST-Bench and found that C-to-safe-Rust transpilation remains a significant challenge.
In a single-shot setting, performance is low across the board. The best-performing model, OpenAI 's o1, correctly solved only 15% of the tasks. Performance improves substantially with iterative self-repair. When provided with compiler and test-failure feedback, the success rate for o1 increases to 37%. Similarly, Claude 3.7 Sonnet 's performance improves from 13% to 32% with a test-based repair strategy.
Our error analysis shows that models struggle most with Rust 's strict static guarantees. The most common errors are type mismatches and violations of Rust 's ownership and borrowing rules. Another frequent issue is the generation of incomplete code, often due to model token limits, which results in unimplemented functions.
Conclusion and Future Work
Our evaluation shows that even state-of-the-art LLMs find safe and idiomatic code migration challenging, with the best approaches succeeding on only about a third of the tasks in CRUST-Bench. This leaves significant room for future systems to improve.
We are eager to see more progress in this area. We hope that CRUST-Bench will serve as a valuable resource for the community to drive research, enabling the systematic evaluation and development of new techniques for automated, safe code migration.